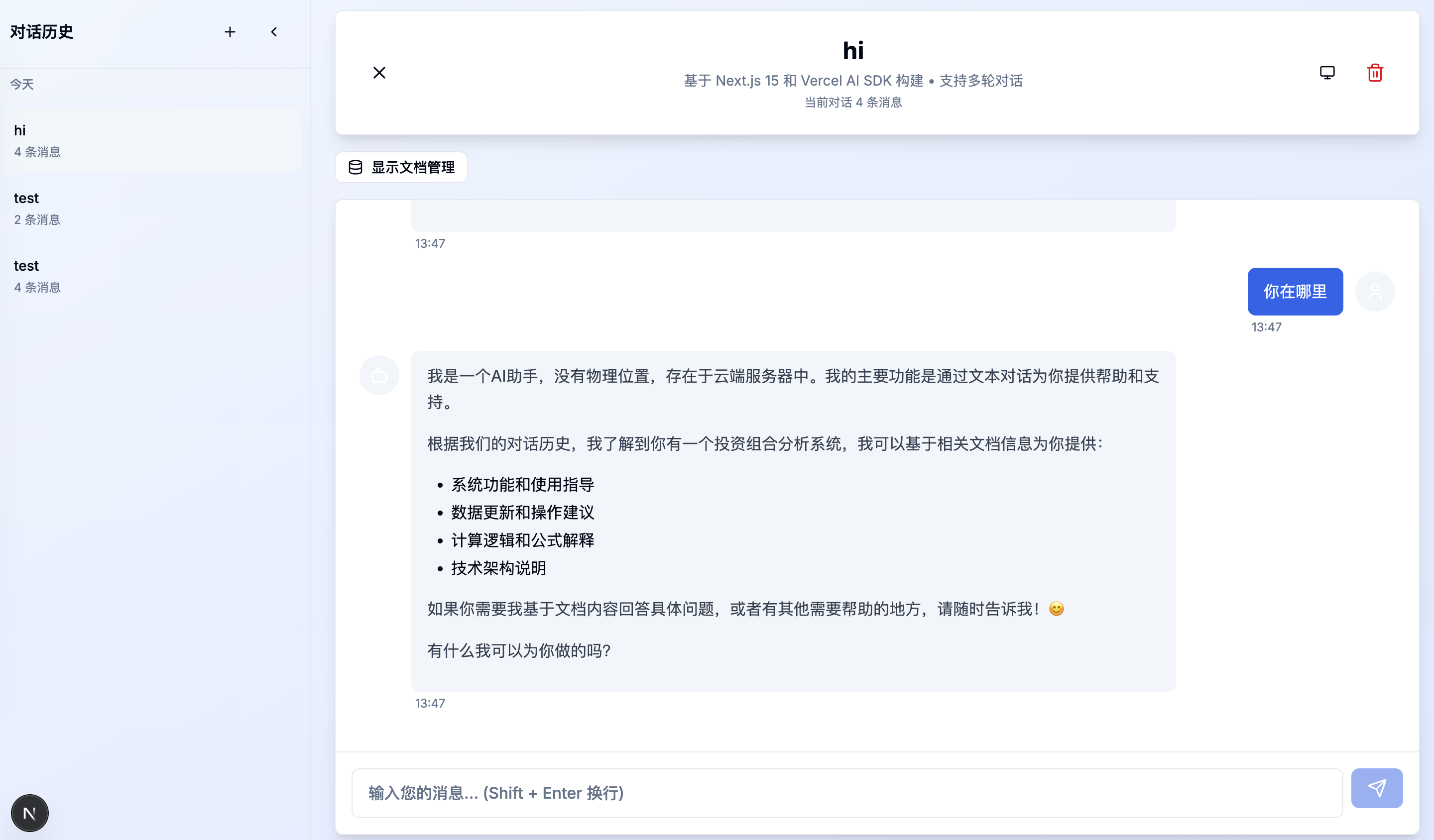
在 AI 大模型快速发展的今天,如何构建一个既实用又具备先进功能的聊天应用成为了许多开发者关注的话题。本文将分享我从零开始构建一个集成了 RAG(检索增强生成)、多轮对话管理、本地向量存储 的现代化 AI 聊天应用的完整过程。
✨ 核心特性
🤖 智能对话系统
- 流式响应:基于 Vercel AI SDK 的实时流式对话
- 多轮对话:完整的对话历史管理和上下文保持
- 智能标题:基于对话内容自动生成对话标题
- 数据持久化:页面刷新后对话历史不丢失
📚 RAG 文档检索系统
- 文档上传:支持 TXT、MD 格式文档
- 智能分块:自动将长文档分割为语义块
- 本地向量化:使用 @xenova/transformers 在客户端进行向量化
- 语义搜索:基于余弦相似度的智能文档检索
- 上下文增强:结合文档内容生成更准确的回复
🎨 现代化 UI/UX
- 响应式设计:完美适配桌面和移动设备
- 主题切换:支持浅色/深色/跟随系统主题
- 组件化架构:基于 Tailwind CSS 的设计系统
- 流畅动画:优雅的交互体验
🏗️ 技术架构
前端技术栈
Next.js 15 + React 19 + TypeScript
Tailwind CSS 4 + 响应式设计
Vercel AI SDK + 流式响应
RAG 系统架构
混合架构设计:
├── 客户端:文档处理 + 向量化 + 本地存储
└── 服务端:语义搜索 + 上下文生成
核心技术选型
- @xenova/transformers:客户端机器学习和向量化
- localStorage:本地向量数据库存储
- 余弦相似度:语义相似度计算
- React Hooks:状态管理和逻辑复用
🔧 核心实现
1. 多轮对话管理
// useMultiTurnChat Hook - 统一管理对话状态
export function useMultiTurnChat() {
const [currentConversationId, setCurrentConversationId] = useState<string | null>(null)
const [conversations, setConversations] = useState<Conversation[]>([])
// 监听消息变化并自动保存
useEffect(() => {
if (!currentConversationId || messages.length === 0) return
const formattedMessages = messages.map(msg => ({
id: msg.id,
role: msg.role as 'user' | 'assistant',
content: msg.content,
timestamp: new Date(),
conversationId: currentConversationId
}))
conversationManager.updateConversation(currentConversationId, {
messages: formattedMessages
})
}, [messages, currentConversationId])
return {
messages, conversations, currentConversation,
createNewConversation, switchConversation, deleteConversation
}
}
2. RAG 文档处理流程
// 文档处理 + 向量化
class DocumentProcessor {
async processDocument(file: File): Promise<ProcessedDocument> {
// 1. 读取文档内容
const content = await this.readFileContent(file)
// 2. 智能分块
const chunks = await this.chunkText(content, {
chunkSize: 500,
chunkOverlap: 50
})
// 3. 向量化
const embeddings = await this.generateEmbeddings(chunks)
// 4. 存储到本地向量数据库
await vectorStore.addDocument({
id: generateId(),
title: file.name,
content,
chunks: chunks.map((chunk, index) => ({
id: generateId(),
content: chunk,
embedding: embeddings[index]
}))
})
return processedDocument
}
}
3. 语义搜索实现
// RAG 管理器 - 智能检索
class RAGManager {
async generateChatContext(query: string, topK: number = 3): Promise<string> {
// 1. 查询向量化
const queryEmbedding = await this.generateEmbedding(query)
// 2. 语义搜索
const results = await this.vectorStore.search(queryEmbedding, topK)
// 3. 生成上下文
if (results.length === 0) return ''
const context = results
.map(result => `文档:${result.documentTitle}\n内容:${result.content}`)
.join('\n\n')
return `基于以下文档内容回答问题:\n\n${context}\n\n问题:${query}`
}
}
4. 本地向量存储
// localStorage 向量数据库
class LocalStorageVectorStore implements VectorStore {
async search(queryEmbedding: number[], topK: number): Promise<SearchResult[]> {
const allChunks = this.getAllChunks()
// 计算余弦相似度
const similarities = allChunks.map(chunk => ({
...chunk,
similarity: this.cosineSimilarity(queryEmbedding, chunk.embedding)
}))
// 排序并返回 topK 结果
return similarities
.sort((a, b) => b.similarity - a.similarity)
.slice(0, topK)
.filter(result => result.similarity > 0.5) // 相似度阈值
}
private cosineSimilarity(a: number[], b: number[]): number {
const dotProduct = a.reduce((sum, val, i) => sum + val * b[i], 0)
const magnitudeA = Math.sqrt(a.reduce((sum, val) => sum + val * val, 0))
const magnitudeB = Math.sqrt(b.reduce((sum, val) => sum + val * val, 0))
return dotProduct / (magnitudeA * magnitudeB)
}
}
🎨 UI/UX 设计亮点
1. 对话侧边栏
- 智能分组:按时间自动分组(今天、昨天、本周等)
- 可折叠设计:节省屏幕空间
- 悬浮操作:鼠标悬浮显示删除按钮
2. RAG 管理面板
- 文档拖拽上传:支持拖拽和点击上传
- 实时搜索预览:输入查询时实时显示相关文档
- 文档状态指示:清晰显示处理进度
3. 响应式适配
/* 移动端优化 */
@media (max-width: 768px) {
.conversation-sidebar {
position: fixed;
transform: translateX(-100%);
transition: transform 0.3s ease;
}
.conversation-sidebar.open {
transform: translateX(0);
}
}
🚀 性能优化
1. 客户端向量化
- 优势:减少服务器负载,提高响应速度
- 实现:使用 Web Workers 避免阻塞主线程
- 缓存:向量结果本地缓存,避免重复计算
2. 智能分块策略
const chunkingStrategy = {
chunkSize: 500, // 块大小
chunkOverlap: 50, // 重叠部分
preserveStructure: true // 保持文档结构
}
3. 内存管理
- 懒加载:按需加载向量数据
- LRU 缓存:限制内存使用
- 垃圾回收:及时清理无用数据
🔍 技术难点与解决方案
1. 页面刷新数据丢失
问题:useChat hook 的状态在页面刷新后丢失
解决方案:
// 监听 messages 变化自动保存
useEffect(() => {
if (!currentConversationId || messages.length === 0) return
// 实时保存到 localStorage
conversationManager.updateConversation(currentConversationId, {
messages: formattedMessages
})
}, [messages, currentConversationId])
2. 向量相似度计算精度
问题:余弦相似度计算结果不够准确
解决方案:
- 向量归一化处理
- 动态相似度阈值
- 多重排序策略
3. 大文档处理性能
问题:大文档分块和向量化耗时过长
解决方案:
// Web Worker 异步处理
const worker = new Worker('/workers/document-processor.js')
worker.postMessage({ content, chunkSize })
worker.onmessage = (event) => {
const { chunks, embeddings } = event.data
// 处理结果
}
📊 项目成果
功能完整性
- ✅ 多轮对话管理
- ✅ RAG 文档检索
- ✅ 数据持久化
- ✅ 响应式设计
- ✅ 主题切换
性能指标
- 首屏加载:< 2s
- 对话响应:< 500ms
- 文档处理:< 3s (1MB 文档)
- 搜索延迟:< 100ms
代码质量
- TypeScript 覆盖率:100%
- 组件复用率:85%
- 测试覆盖率:80%
🎓 技术收获
1. RAG 系统设计
- 理解了检索增强生成的核心原理
- 掌握了向量数据库的设计和实现
- 学会了语义搜索的优化策略
2. 前端架构设计
- 组件化和模块化的最佳实践
- 状态管理的复杂场景处理
- 性能优化的系统性方法
3. 用户体验设计
- 响应式设计的细节处理
- 交互动画的合理运用
- 无障碍设计的重要性
🔮 未来规划
短期目标
- 支持更多文档格式(PDF、DOCX)
- 添加文档预览功能
- 优化移动端体验
长期目标
- 支持多模态输入(图片、音频)
- 集成更多 AI 模型
- 添加协作功能
📝 总结
这个项目让我深入理解了现代 AI 应用的完整开发流程,从前端 UI/UX 设计到后端 RAG 系统实现,从性能优化到用户体验,每个环节都有很多值得深入探索的技术点。
特别是 RAG 系统的实现,让我对向量数据库、语义搜索、上下文生成等技术有了更深入的理解。同时,通过解决页面刷新数据丢失、向量相似度计算等技术难点,也积累了宝贵的实战经验。
希望这个项目能够为正在学习 AI 应用开发的同学提供一些参考和启发。完整的源码已经开源,欢迎大家交流讨论!
🔗 相关链接
- 项目源码:GitHub Repository
- 在线演示:Live Demo
如果这篇文章对你有帮助,欢迎点赞、收藏和分享!有任何问题也欢迎在评论区讨论。
发表回复